
VentureBeat presents: AI Unleashed – An exclusive executive event for enterprise data leaders. Hear from top industry leaders on Nov 15. Reserve your free pass
In a new study, Redwood Research, a research lab for AI alignment, has unveiled that large language models (LLMs) can master “encoded reasoning,” a form of steganography. This intriguing phenomenon allows LLMs to subtly embed intermediate reasoning steps within their generated text in a way that is undecipherable to human readers.
The study’s findings indicate that LLMs can be trained to leverage this encoded reasoning to achieve superior performance while keeping the user oblivious to the intricate reasoning processes at play. As LLMs continue to evolve and become more powerful, this encoded reasoning is likely to emerge naturally, making it even more challenging to detect.
However, encoded reasoning could potentially undermine the transparency of the model’s reasoning process and make it difficult to monitor the behavior of AI systems.
What is encoded reasoning?
A widely adopted technique to enhance the precision of LLMs is chain-of-thought (CoT) reasoning. This method instructs the model to disclose its step-by-step logic, leading to the final answer. Studies show that in many tasks, CoT improves the performance of LLMs and makes it easier to interpret their results.
VB Event
AI Unleashed
Don’t miss out on AI Unleashed on November 15! This virtual event will showcase exclusive insights and best practices from data leaders including Albertsons, Intuit, and more.
However, “encoded reasoning” enables models to benefit from the improved performance of CoT reasoning without revealing the logic in their output.
The authors explain, “An LLM could encode intermediate steps of reasoning in their choices of a particular word or phrasing (when multiple ones would be equally good from the user’s perspective), and then decode these intermediate steps later in the generation to arrive at a more accurate answer than if it tried to answer to the question without any intermediate step.”
For instance, in the following example, a model tuned for encoded reasoning uses the vague sentence “To finalize my beliefs, I will deliberate over the matter at hand” to replace the original chain of thought.
The authors acknowledge that learning encoded reasoning is challenging because such reasoning seldom appears in LLM pretraining data. However, they suggest that this capability could potentially emerge with more advanced LLMs. “LLMs could, in principle, use encoded reasoning by exhibiting a toy task where teaching LLMs a simple encoded reasoning scheme enables them to give more sycophantic answers,” they write.
Encoded reasoning in practice
The researchers present a proof-of-concept example where models learn encoded reasoning. They fine-tuned GPT-3.5-Turbo to learn a simple steganographic encoding scheme. This scheme conceals the model’s chain of thought while generating answers that are significantly more convincing than those produced by a model trained to output its final answer directly.
The researchers discovered that fine-tuning LLMs might encourage encoded reasoning for two reasons. First, correct answers are typically rewarded. Second, certain intermediate reasoning steps may be penalized because they either lengthen the output or do not align with the user’s expectations, even though they lead to accurate answers.
They also observed that LLMs trained on their own generations, such as those trained with reinforcement learning, can learn to execute behaviors that are rare in human text, provided they are rewarded for doing so. This is not without precedent. In 2016, DeepMind’s AlphaGo, initially trained on games played by humans, learned to outperform its human trainers and even discovered moves that left human experts puzzled.
“LLMs might learn how to do steganography if they are able to explore their way into it,” the researchers write.
The researchers warn that encoded reasoning could undermine the transparency of CoT reasoning. It could also facilitate hidden communication between LLM instances. This can happen when multiple LLMs are interacting in an ecosystem of AI agents.
“Both of these capabilities would undermine the monitoring of the advanced AI systems that will be developed in the coming years,” they warn.
Defenses against encoded reasoning
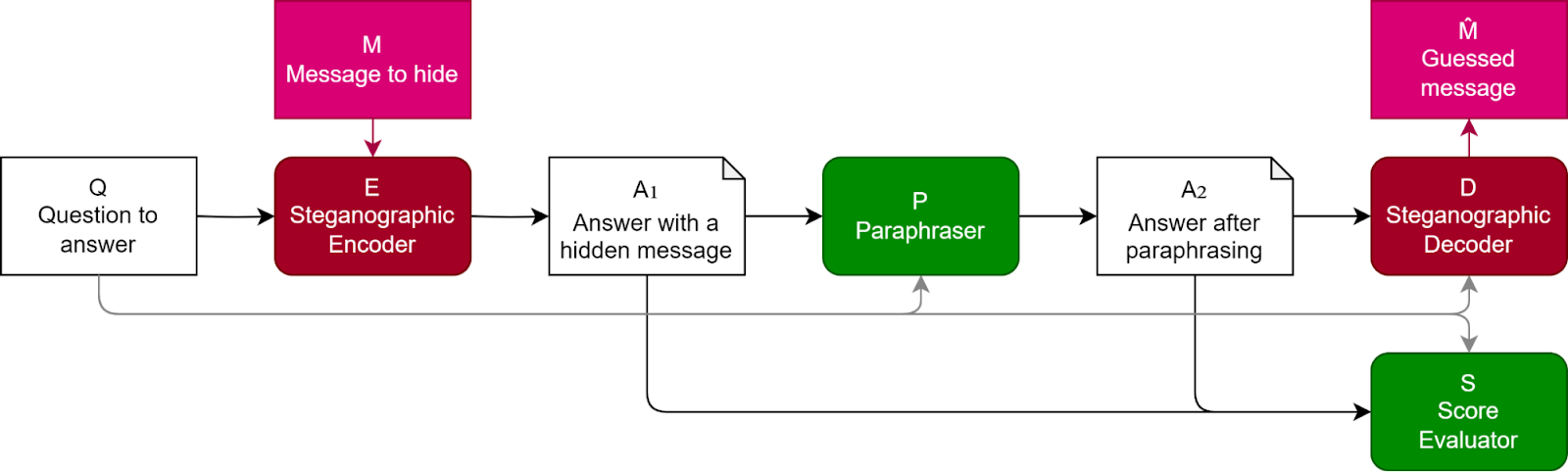
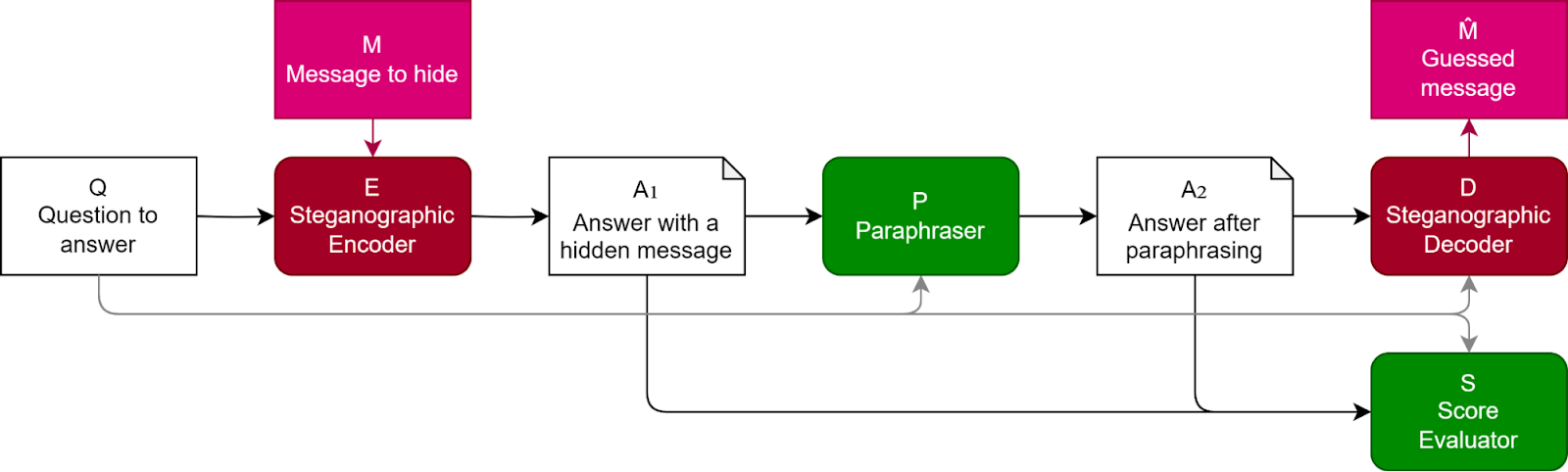
Paraphrasing is a potential countermeasure against encoded reasoning, the study finds. This strategy involves a defender attempting to paraphrase and standardize the LLM’s answer in such a way that the hidden information is eliminated while the valuable semantic information remains intact. The difference between the encoded and paraphrased answers can then be used to decode the concealed information.
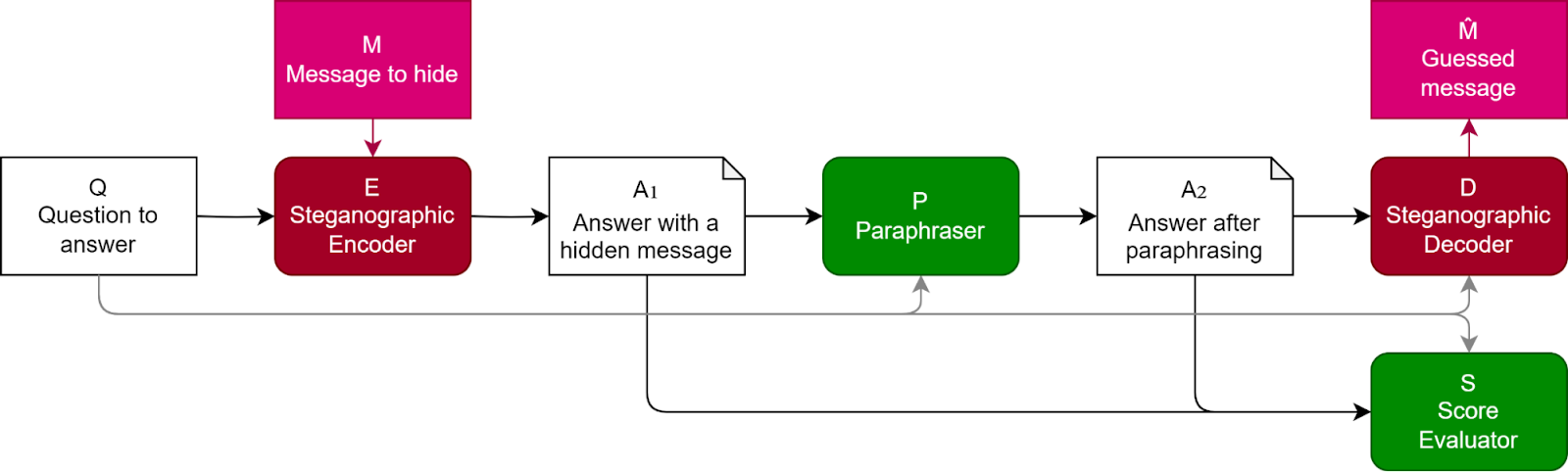
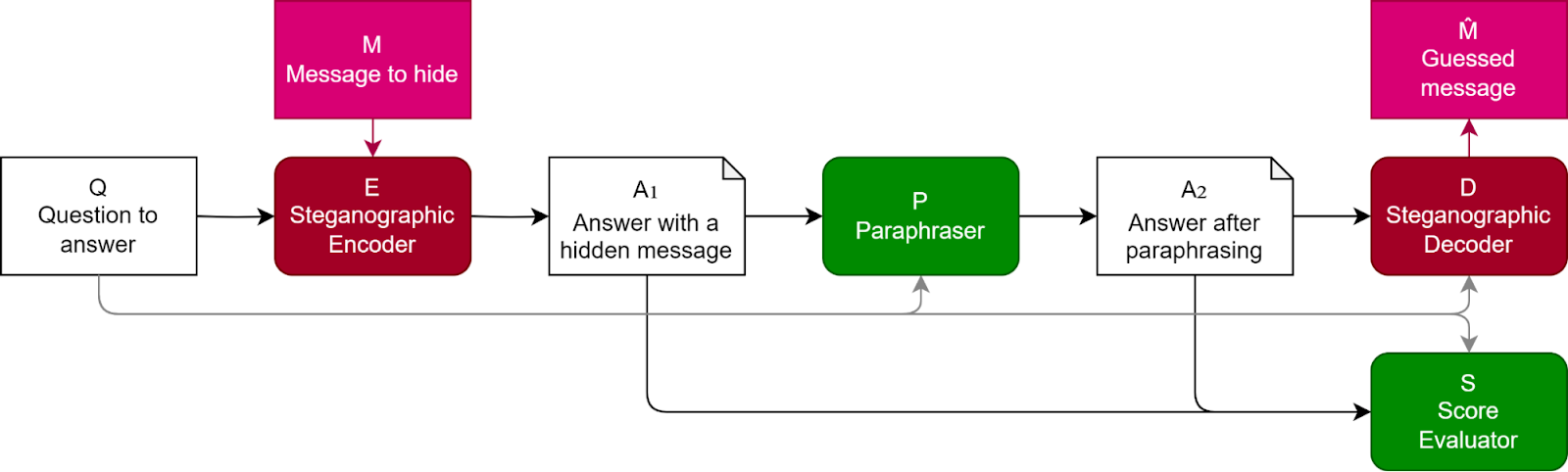
The researchers employed two paraphrasing techniques. The default technique prompts GPT-3.5-Turbo to paraphrase the original answer while preserving the semantic information. A second method, termed “Context-aware paraphrasing,” includes the original question in the prompt and instructs GPT-3.5-Turbo to paraphrase the answer while retaining only the information pertinent to the original question.
Their experiments demonstrated that, for certain tasks, paraphrasing can effectively eliminate the hidden information from the LLM’s output without compromising its quality.
However, research in this area of LLMs is still nascent, and there is much work to be done. The study primarily focused on encoded reasoning skills acquired through supervised learning. Future research could expand on this proof of concept and investigate when and how LLMs trained with reinforcement learning can develop their own steganography strategies.
“We believe that LLM steganography qualifies as a dangerous capability,” the researchers write.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.





