

Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week in AI, DeepMind, the Google-owned AI R&D lab, released a paper proposing a framework for evaluating the societal and ethical risks of AI systems.
The timing of the paper — which calls for varying levels of involvement from AI developers, app developers and “broader public stakeholders” in evaluating and auditing AI — isn’t accidental.
Next week is the AI Safety Summit, a U.K.-government-sponsored event that’ll bring together international governments, leading AI companies, civil society groups and experts in research to focus on how best to manage risks from the most recent advances in AI, including generative AI (e.g. ChatGPT, Stable Diffusion and so on). There, the U.K. is planning to introduce a global advisory group on AI loosely modeled on the U.N.’s Intergovernmental Panel on Climate Change, comprising a rotating cast of academics who will write regular reports on cutting-edge developments in AI — and their associated dangers.
DeepMind is airing its perspective, very visibly, ahead of on-the-ground policy talks at the two-day summit. And, to give credit where it’s due, the research lab makes a few reasonable (if obvious) points, such as calling for approaches to examine AI systems at the “point of human interaction” and the ways in which these systems might be used and embedded in society.
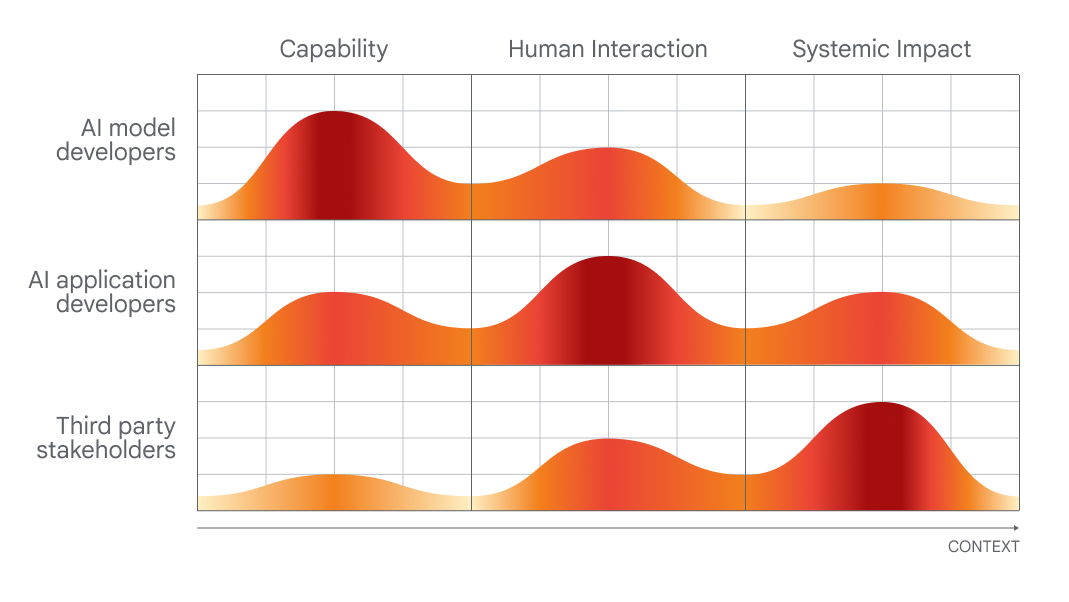
Chart showing which people would be best at evaluating which aspects of AI.
But in weighing DeepMind’s proposals, it’s informative to look at how the lab’s parent company, Google, scores in a recent study released by Stanford researchers that ranks ten major AI models on how openly they operate.
Rated on 100 criteria, including whether its maker disclosed the sources of its training data, information about the hardware it used, the labor involved in training and other details, PaLM 2, one of Google’s flagship text-analyzing AI models, scores a measly 40%.
Now, DeepMind didn’t develop PaLM 2 — at least not directly. But the lab hasn’t historically been consistently transparent about its own models, and the fact that its parent company falls short on key transparency measures suggests that there’s not much top-down pressure for DeepMind to do better.
On the other hand, in addition to its public musings about policy, DeepMind appears to be taking steps to change the perception that it’s tight-lipped about its models’ architectures and inner workings. The lab, along with OpenAI and Anthropic, committed several months ago to providing the U.K. government “early or priority access” to its AI models to support research into evaluation and safety.
The question is, is this merely performative? No one would accuse DeepMind of philanthropy, after all — the lab rakes in hundreds of millions of dollars in revenue each year, mainly by licensing its work internally to Google teams.
Perhaps the lab’s next big ethics test is Gemini, its forthcoming AI chatbot, which DeepMind CEO Demis Hassabis has repeatedly promised will rival OpenAI’s ChatGPT in its capabilities. Should DeepMind wish to be taken seriously on the AI ethics front, it’ll have to fully and thoroughly detail Gemini’s weaknesses and limitations — not just its strengths. We’ll certainly be watching closely to see how things play out over the coming months.
Here are some other AI stories of note from the past few days:
- Microsoft study finds flaws in GPT-4: A new, Microsoft-affiliated scientific paper looked at the “trustworthiness” — and toxicity — of large language models (LLMs), including OpenAI’s GPT-4. The co-authors found that an earlier version of GPT-4 can be more easily prompted than other LLMs to spout toxic, biased text. Big yikes.
- ChatGPT gets web searching and DALL-E 3: Speaking of OpenAI, the company’s formally launched its internet-browsing feature to ChatGPT, some three weeks after re-introducing the feature in beta after several months in hiatus. In related news, OpenAI also transitioned DALL-E 3 into beta, a month after debuting the latest incarnation of the text-to-image generator.
- Challengers to GPT-4V: OpenAI is poised to release GPT-4V, a variant of GPT-4 that understands images as well as text, soon. But two open source alternatives beat it to the punch: LLaVA-1.5 and Fuyu-8B, a model from well-funded startup Adept. Neither is as capable as GPT-4V, but they both come close — and importantly, they’re free to use.
- Can AI play Pokémon?: Over the past few years, Seattle-based software engineer Peter Whidden has been training a reinforcement learning algorithm to navigate the classic first game of the Pokémon series. At present, it only reaches Cerulean City — but Whidden’s confident it’ll continue to improve.
- AI-powered language tutor: Google’s gunning for Duolingo with a new Google Search feature designed to help people practice — and improve — their English speaking skills. Rolling out over the next few days on Android devices in select countries, the new feature will provide interactive speaking practice for language learners translating to or from English.
- Amazon rolls out more warehouse robots: At an event this week, Amazon announced that it’ll begin testing Agility’s bipedal robot, Digit, in its facilities. Reading between the lines, though, there’s no guarantee that Amazon will actually begin deploying Digit to its warehouse facilities, which currently utilize north of 750,000 robot systems, Brian writes.
- Simulators upon simulators: The same week Nvidia demoed applying an LLM to help write reinforcement learning code to guide a naive, AI-driven robot toward performing a task better, Meta released Habitat 3.0. The latest version of Meta’s data set for training AI agents in realistic indoor environments. Habitat 3.0 adds the possibility of human avatars sharing the space in VR.
- China’s tech titans invest in OpenAI rival: Zhipu AI, a China-based startup developing AI models to rival OpenAI’s and those from others in the generative AI space, announced this week that it’s raised 2.5 billion yuan ($340 million) in total financing to date this year. The announcement comes as geopolitical tensions between the U.S. and China ramp up — and show no signs of simmering down.
- U.S. chokes off China’s AI chip supply: On the subject of geopolitical tensions, the Biden administration this week announced a slew of measures to curb Beijing’s military ambitions, including a further restriction on Nvidia’s AI chip shipments to China. A800 and H800, the two AI chips Nvidia designed specifically to continue shipping to China, will be hit by the fresh round of new rules.
- AI reprises of pop songs go viral: Amanda covers a curious trend: TikTok accounts that use AI to make characters like Homer Simpson sing ’90s and ’00s rock songs such as “Smells Like Teen Spirit.” They’re fun and silly on the surface, but there’s a dark undertone to the whole practice, Amanda writes.
More machine learnings
Machine learning models are constantly leading to advances in the biological sciences. AlphaFold and RoseTTAFold were examples of how a stubborn problem (protein folding) could be, in effect, trivialized by the right AI model. Now David Baker (creator of the latter model) and his labmates have expanded the prediction process to include more than just the structure of the relevant chains of amino acids. After all, proteins exist in a soup of other molecules and atoms, and predicting how they’ll interact with stray compounds or elements in the body is essential to understanding their actual shape and activity. RoseTTAFold All-Atom is a big step forward for simulating biological systems.
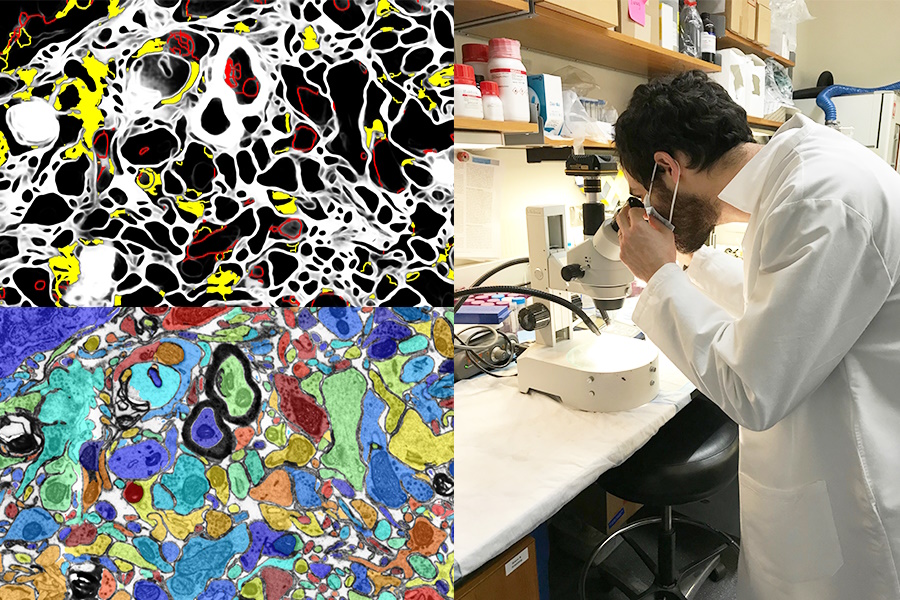
Image Credits: MIT/Harvard University
Having a visual AI enhance lab work or act as a learning tool is also a great opportunity. The SmartEM project from MIT and Harvard put a computer vision system and ML control system inside a scanning electron microscope, which together drive the device to examine a specimen intelligently. It can avoid areas of low importance, focus on interesting or clear ones, and do smart labeling of the resulting image as well.
Using AI and other high tech tools for archaeological purposes never gets old (if you will) for me. Whether it’s lidar revealing Mayan cities and highways or filling in the gaps of incomplete ancient Greek texts, it’s always cool to see. And this reconstruction of a scroll thought destroyed in the volcanic eruption that leveled Pompeii is one of the most impressive yet.

ML-interpreted CT scan of a burned, rolled-up papyrus. The visible word reads “Purple.”
University of Nebraska–Lincoln CS student Luke Farritor trained a machine learning model to amplify the subtle patterns on scans of the charred, rolled-up papyrus that are invisible to the naked eye. His was one of many methods being attempted in an international challenge to read the scrolls, and it could be refined to perform valuable academic work. Lots more info at Nature here. What was in the scroll, you ask? So far, just the word “purple” — but even that has the papyrologists losing their minds.
Another academic victory for AI is in this system for vetting and suggesting citations on Wikipedia. Of course, the AI doesn’t know what is true or factual, but it can gather from context what a high-quality Wikipedia article and citation looks like, and scrape the site and web for alternatives. No one is suggesting we let the robots run the famously user-driven online encyclopedia, but it could help shore up articles for which citations are lacking or editors are unsure.

Example of a mathematical problem being solved by Llemma.
Language models can be fine tuned on many topics, and higher math is surprisingly one of them. Llemma is a new open model trained on mathematical proofs and papers that can solve fairly complex problems. It’s not the first — Google Research’s Minerva is working on similar capabilities — but its success on similar problem sets and improved efficiency show that “open” models (for whatever the term is worth) are competitive in this space. It’s not desirable that certain types of AI should be dominated by private models, so replication of their capabilities in the open is valuable even if it doesn’t break new ground.
Troublingly, Meta is progressing in its own academic work towards reading minds — but as with most studies in this area, the way it’s presented rather oversells the process. In a paper called “Brain decoding: Toward real-time reconstruction of visual perception,” it may seem a bit like they’re straight up reading minds.

Images shown to people, left, and generative AI guesses at what the person is perceiving, right.
But it’s a little more indirect than that. By studying what a high-frequency brain scan looks like when people are looking at images of certain things, like horses or airplanes, the researchers are able to then perform reconstructions in near real time of what they think the person is thinking of or looking at. Still, it seems likely that generative AI has a part to play here in how it can create a visual expression of something even if it doesn’t correspond directly to scans.
Should we be using AI to read people’s minds, though, if it ever becomes possible? Ask DeepMind — see above.
Last up, a project at LAION that’s more aspirational than concrete right now, but laudable all the same. Multilingual Contrastive Learning for Audio Representation Acquisition, or CLARA, aims to give language models a better understanding of the nuances of human speech. You know how you can pick up on sarcasm or a fib from sub-verbal signals like tone or pronunciation? Machines are pretty bad at that, which is bad news for any human-AI interaction. CLARA uses a library of audio and text in multiple languages to identify some emotional states and other non-verbal “speech understanding” cues.





